2. AutoRAG 속 Retrieval token metric 파해치기
0. Retrieval token metric in AutoRAG 현재 AutoRAG에서, Retrieval token metric은 Passage Compressor Node 에서만 사용하고 있다. Compress된 Passage를 Answer_gt와 비교해서 성

Quick context
First, this page captures one concrete build-log step, research note, or project lesson from Jeffrey Kim.
Next, use the tags, related reading, and home archive to move from this note to deeper material in the same topic cluster.
Finally, follow the RSS feed if you want the next experiment, retrospective, or paper review as soon as it ships.
제가 직접 작성한 것이 아닌 AutoRAG를 같이 만든 [김병욱](https://www.linkedin.com/in/autorag-bwook/) 연구원이 쓴 글입니다.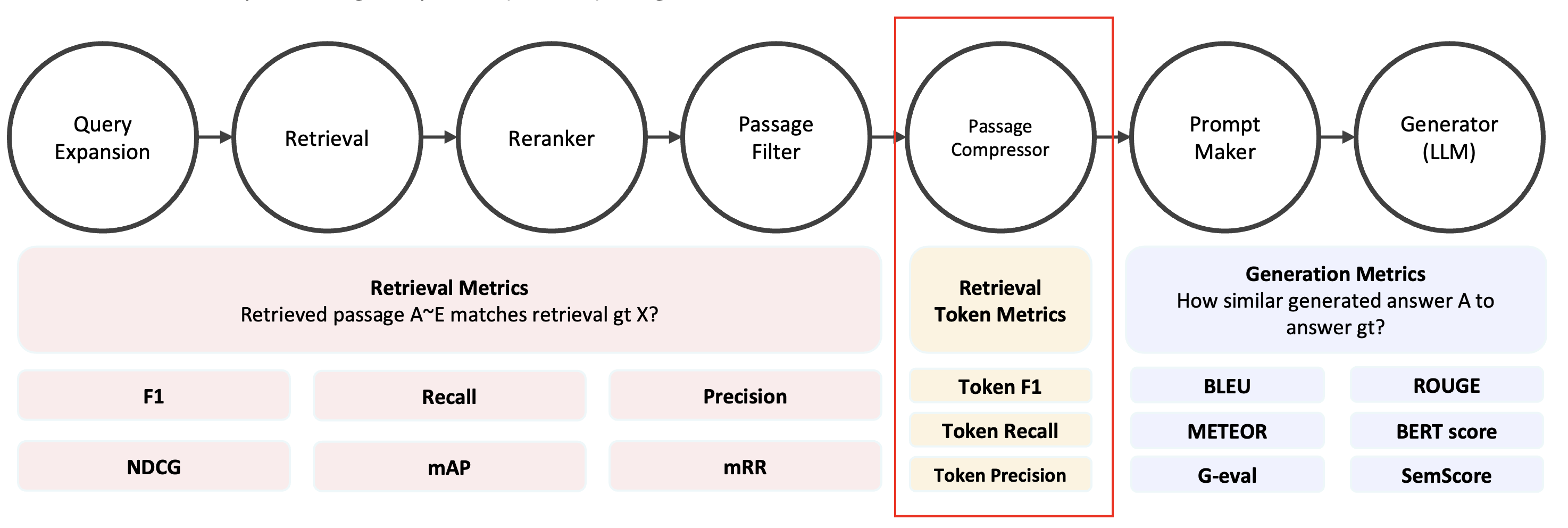
- Retrieval Metric이 궁금하다면? => 링크
0. Retrieval token metric in AutoRAG
현재 AutoRAG에서, Retrieval token metric은 Passage Compressor Node 에서만 사용하고 있다. Compress된 Passage를 Answer_gt와 비교해서 성능을 측정하는 구조다.
Passage와 Answer gt를 비교할 때는 token 단위로 비교를 하는데, 이는 example을 보며 확인해보자
✅ Basic Example
answer gt = ['Do you want to buy some?']
result = ['Do you want to buy some?', 'I want to buy some', 'I want to buy some water']
이제 gt와 result를 token 단위로 쪼개보자
- gt_tokens은 총 6개의 token으로 이루어져 있다
['do', 'you', 'want', 'to', 'buy', 'some'] - result_tokens은 다음과 같다
['do', 'you', 'want', 'to', 'buy', 'some'], ['I', 'want', 'to', 'buy', 'some'], ['I', 'want', 'to', 'buy', 'some', 'water']
이 때, gt와 result에 서로 겹치는 token 수를 살펴보자
- 첫 번째는 6개의 token 모두가 gt와 겹친다. 따라서 겹치는 token 수는 6개다.
- 두 번째는 ‘I’를 제외한 4개의 token이 겹친다.
- 세 번째는 ‘I’와 ‘water’를 제외한 4개의 token이 겹친다.
1. Token Precision
📌 Definition
겹치는 토큰 수 / result의 token 길이
✅ Apply Basic Example
첫 번째는 6/6 = 1
두 번째는 4/5 = 0.8
세 번째는 4/6 = 2/3 = 0.666…
따라서, token precision은 셋의 평균인 0.822… 이다
2. Token Recall
📌 Definition
겹치는 토큰 수 / gt의 token 길이
✅ Apply Basic Example
첫 번째는 6/6 = 1
두 번째는 4/6 = 0.666…
세 번째는 4/6 = 2/3 = 0.666…
따라서, 다음 셋의 평균인 0.777…가 평균이 된다
3. Token F1
📌 Definition
F1 score는 Precision과 Recall의 조화평균이다.

✅ Apply Basic Example
Precision = 0.822…
Recall = 0.777…
Therefore, F1 Score = 0.797979…